What is the Difference Between validity from reliability?
Validity and reliability are both concerned with the accuracy of a method's measurements:
The consistency of a measure: that is, if the outcomes can be repeated under the same circumstances—is referred to as reliability.
The accuracy of a measure: that is, if the outcomes actually reflect what the measure is intended to assess—is referred to as validity.
In your day-to-day life, do you use the terms reliable and valid interchangeably? I am sure you would say, at least sometimes, but in the case of research, you cannot make this mistake. The terms “VALIDITY” and “RELIABILITY” are not the same things. Let us understand how?
In statistics and research or when you talk specifically in the context of data analysis, reliability means how easily replicable one specific outcome is. For instance, if you measure a cup of milk three times, it would be the same each of the times. This means what? This means that the result is reliable.
On the other hand, validity talks in the context of accuracy. Accuracy of the measurement. What does this imply? It implies that if a standard cup of milk measures 50 ml and you are also measuring a cup of milk, it should be 50 ml.
Reliability and validity go hand in hand in research, though not synonyms but they are intertwined. So even if the results show consistency, which means reliability but the measuring scale is distorted, the results are ultimately going to be invalid.
Here is the catch then, data must be reliable and valid which means consistent and accurate so that logical and useful conclusions can be drawn. Let us help you to understand how to assess the reliability and validity of the data and its application in a very simple and hands-on manner.
What is Reliability?
So, we just understood that when we get consistency in our measurement, like the cup of milk example, it is reliable. But you need to know that in data analysis, reliability does not mean the outcome or result is going to be the same. It means it is going to be in the same range. Let us understand with another relatable example, in one test if you scored 95% and in the other two tests you scored 96% and 94% respectively. Your results can be called consistent or reliable. The condition to be met here is that they should be within the specified error margin. Testing the reliability of your data helps to assess the consistency of your results.
What is validity?
A specific measurement or test is valid only when it correlates with the expected outcome. It examines the accuracy of your results.
Things can get tricky here sometimes, this statement can confuse you.
To establish the validity of a test, the results must be consistent.

You will get the meaning and understanding of this statement as you reach the end of this article.
Validity and reliability are easy to establish when it comes to scientific experiments. For instance, to conclude that a thousand meters are equivalent to one kilometer, if I repeat the experiment a couple of times and get the same result, consistency, and accuracy, both will be established. Similarly in the case of measuring depth, width, height, thickness, or anything that is easy to quantify valid answers are likely to be reliable.
But what happens in the case of social experiments?
Are reliability and validity strong indicators of each other? What do you think so?
For instance, most people would say that people who live in big cities are able to speak better English. This can be true for many cases, where you could find people in metro cities such as Delhi or Mumbai who speak very good English but the truth is that even people in rural India can speak good English if they have received the education so it is got to do with education and not location. In the case of social sciences, we can say that reliable answers are not always valid answers but if the answer is valid, it’s necessarily reliable.
I hope that with this simple example, the difference in the application of reliability and validity is clear to you.
Errors in Reliability and Validity
i. Random Errors:
This term is used to describe all the probable chances or the random factors which can cause the errors. In other words, these are the inconsistent errors that take place by chance. Because random errors occur by chance, these are unpredictable as well as transitory in nature. These errors include sampling errors, those unpredictable fluctuations that can happen without any anticipation. For instance, change in the mood of the respondent to answer with sincerity. The number of random errors in an experiment has an inverse relationship with the reliability of the instrument. This means higher random errors, lower reliability, and vice versa.
ii. Systematic Errors:
Systematic or non-random errors are the constant biases in the measurement. Let us look at some examples of systematic errors. The thermometer in your house always shows the temperature 2 degrees higher than it is. Your wall clock displays the time 30 minutes behind the actual time. There is again an inverse relationship between systematic error and validity, like the way it is for random error and reliability
Assessment of Reliability and Validity
i. Assessing Reliability
When we are assessing reliability, we attempt to know if it is possible to replicate reliability. Some variables will of course have to be changed to assess the reliability and these could be pertaining to time, observers, or items.
In case the main factor that you are trying to change when performing the reliability test is time, then the assessment is called a test-retest reliability
But then that is not the only way to do it and if you try to test the reliability by changing the items and this checks the internal consistency of the scale.
Not just these two, it is also possible to measure by using different observers and keep the item and instrument the same. This is called an inter-rater reliability test.
ii. Reliability Testing Methods:
As we discussed above, reliability has categorically got to do with consistency in the results. It means the extent to which an experiment, test, or measurement procedure yields consistent results in repeated trials. As we discussed above, the presence of random errors in reliability is always there so it is next to impossible to achieve 100 percent reliable measure as the risk of some degree of unreliability is always present.
Let me explain to you the application of the basic methods that are used for measuring reliability.
i. Test-Retest Method: This method is the basic method where the same instrument is used on the same set of respondents in similar conditions but at different times to understand that with repeated execution of the same instrument and other things also remaining the same, what amount of consistency is maintained in the results. The main purpose of using this method is to uncover the random errors. When the results are highly consistent, the measurements are said to be reliable and good. Here reliability is equal to the correlation of the two test scores taken among the same respondents at different times.
There are a few concerns with this test when it comes to the execution and practical applicability, one is that there may be challenges in ensuring the same set of respondents fill out the questionnaire or take the survey the second time or more. In addition to this, the second time is never independent of the impact of the first time. The responses of the first time may impact the options the same respondent chooses the second time. And lastly, any kind of change in the environment that is uncontrollable can impact the responses and give you less accuracy about the reliability of the instrument.
ii. Equivalent Form Method: With the pitfalls that are associated with the test-retest method, there is another way in which reliability can be assessed. Here two equivalent forms are created with a similar ability to be able to produce results that have a strong correlation. The way to do it is to create a large set of questions that are about the same construct and then randomly divide them into two sets. The same respondents must fill both the sets and then upon evaluation if a strong correlation exists between the sets, then the reliability is said to be high. This method also has its own set of problems of being able to create two instruments that are equivalent and then it also involves double the investment of time and resources in doing so. What do you think about it?
iii. Internal consistency and split-half method: these methods for establishing reliability are based on internal consistency to produce the same results of different samples in the same time period. This is a test of equivalence. The split-half method measures the reliability of an instrument by dividing the set of measurement items into two halves and then correlating the results. For example, if we are interested the psychometric analysis to check the self-worth of a respondent then the same question can be asked in different ways as depicted below
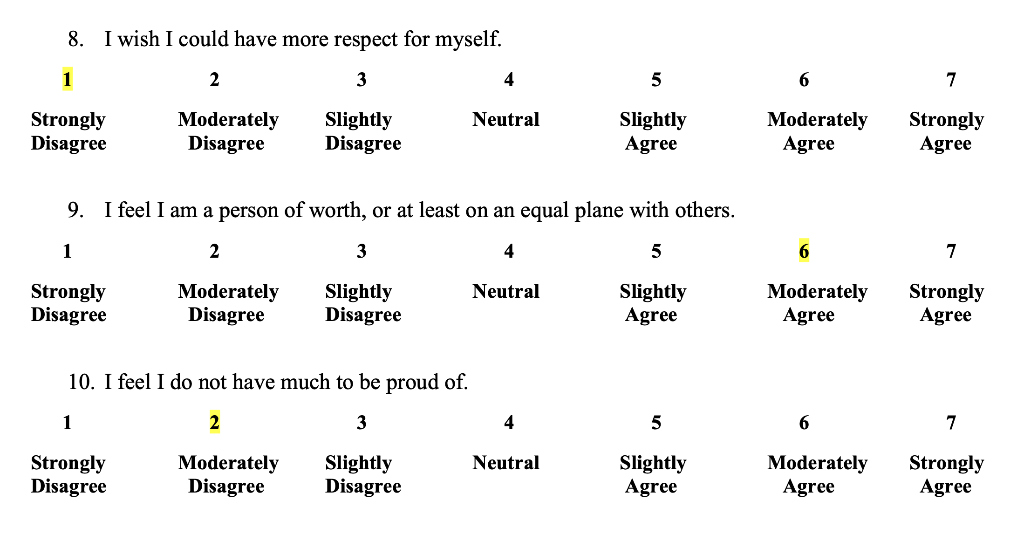
To be reliable, the answers to these two questions should be consistent. The problem with this method is that different "splits" can result in different coefficients of reliability. To overcome this problem, researchers use the Cronbach alpha (α) technique
Assessing Validity
Validity is defined as the ability of an instrument to measure what the researcher intends to measure. There are several different types of validity in social science research. Each takes a different approach to assessing the extent to which a measure measures what the researcher intends to measure. Each type of validity has different meanings, uses, and limitations.
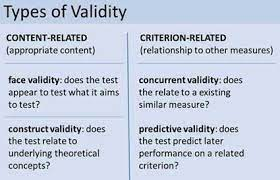
Assessment of the validity is going to be slightly more challenging for you than the assessment of reliability but it is not very difficult once you know that validity is categorized under two sections, which are internal and external and it can be assessed by four commonly used techniques.
The first one is content validity and it is used to measure if the test is covering the entire relevant content and giving the outcome that you are expecting.to
The other one is criterion validity which compares the results that you are supposed to get based on the chosen criteria. It can be measured in two ways which are predictive and concurrent.
The next two types are face and construct validity which are slightly trickier and are based on anticipation of how to assume a test to be.
i. Face Validity: The weakest approach to measure validity is this method with a lot of subjectivity involved in doing so. It measures what it purports to measure and this method purely relies on the judgment of the researcher or a group of seasoned researchers. It is a tricky technique with a lot of subjectivity and relies on the wisdom of the researchers which makes it not a good option to choose from.
ii. Content Validity: in terms of being a good or bad measure for validity assessment, it is considered equivalent to face validity as it relies on the expertise of the researchers to know that all measures or facets of the construct are covered well enough. To get content validity the literature review needs to be connected to the instrument designed and it is analyzed that each of the dimensions of the construct is being measured properly.
iii. Criterion Validity: Criterion Validity measures how well a measurement predicts an outcome based on information from other variables. Criterion validity is a type of validity that examines whether scores on one test are predictive of performance on another. For example, if employees take a psychometric test, the employer would like to know if this test predicts actual job performance. If a psychometric test rightly predicts job performance, then it has criterion validity.
iv. Construct Validity: Construct validity is the degree to which an instrument represents the construct it purports to represent. Construct validity concerns the identification of the causes, effects, settings, and participants that are present in a study. For instance, a drug to cure a disease might have an effect not because of the salt present in it or the way the ingredients are absorbed into the bloodstream of the patient but because of its placebo effects. Another example of convergent validity, which is a type of construct validity is the Self-esteem rating scale which examines a construct that is quite abstract: self-esteem. To determine the construct validity of a self-esteem rating scale, the researcher could compare it to different standardized self-esteem rating scales to see if there is some relationship or similarity.
Conclusion
Validity and reliability are extremely critical for achieving accurate and consistent results in research. While reliable results do not always imply validity, validity establishes that a result is reliable. Validity is always determined based on previous results (standards), whereas reliability is dependent on the consistency of the results.